[Oracle] 2020.12.18. day_40 order by, 순위함수(rank() over(), rownumber() over())
2020. 12. 18. 12:41ㆍWeb_Back-end/Oracle

◎ order by절 : 정렬
| 정렬 | order by | |
| 조회된 레코드를 오름차순, 내림차순으로 만들어 조회하는 것 | ||
| 기본정렬 : 오름차순정렬 | ||
| 모든 데이터를 정렬할 수 있다 | ||
| 사용법 | order by 정렬할컬럼명 asc, 정렬할컬럼명 asc,,,,,, (asc : 오름차순정렬 -명시할필요없다 desc : 내림차순정렬) |
|
| 문자열이 숫자를 가질 때에는 자릿수의 정렬 |
○ order by 사용해보기
| 기본이 empno(첫번째) 오름차순임을 알 수 있다 |
select empno, ename from emp; |
 |
| ename 오름차순 기준으로 정렬 | select empno, ename from emp order by ename asc; |
 |
| 사원명의 내림차순(desc) 정렬 | select empno, ename from emp order by ename desc; |
 |
| 사원번호, 사원명, 연봉을 조회 단, 연봉의 내림차순 정렬 |
select empno, ename, sal from emp order by sal desc; |
 |
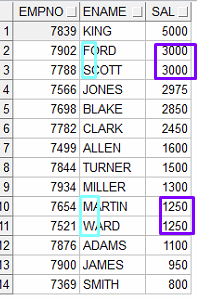
| 사원번호, 사원명, 연봉을 조회 단, 연봉의 내림차순 정렬 + 같은 연봉이 있다면 사원명의 오름차순으로 정렬 첫번째 정렬조건으로 같은 조건이 있다면, 두번째 정렬조건을 줄 수 있다 (계속 같은 조건이 생긴다면 2,3,,,,번째 정렬조건 만들 수 있다) |
select empno, ename, sal from emp order by sal desc, ename asc; |
 |
○ 문자열이 숫자를 가질 때에는 자릿수의 정렬 연습해보기
| 문자열컬럼 | 문자열 정렬 | 정렬해보기 |
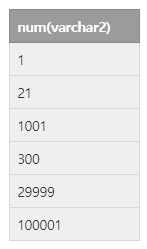 |
좌측 문자열 컬럼 정렬해보기 order by num 문자열정렬은 자릿수의 정렬이므로 첫번째자리정렬 -> 두번째자리정렬 ,,, 마지막자리정렬 순으로 정렬된다 |
 |
| 파일명 정렬도 같은 순이다 따라서 2월 1일 , 12월 1일 파일을 정렬하려면 02월 1일 12월 1일 이렇게 네이밍을 해야한다 |
||
| 테이블 생성해서 연습해보기 | ||
| 문자열 컬럼을 가진 테이블 생성 |
create table test_orderby( num varchar2(10) ); insert into test_orderby(num) values(1); insert into test_orderby(num) values(11); insert into test_orderby(num) values(201); insert into test_orderby(num) values(10009); insert into test_orderby(num) values(2005); insert into test_orderby(num) values(3); insert into test_orderby(num) values(4); insert into test_orderby(num) values(321); insert into test_orderby(num) values(30001); commit; |
 |
| 정렬 | select num from test_orderby order by num; 오름차순으로 정렬할 때에는 기본설정이 오름차순이므로 asc를 생략할 수 있다 문자열(varchar2, char) 데이터형이 숫자를 가지면 자릿수의 정렬 수행함을 알 수 있다 |
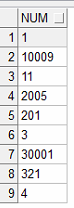 일반 사용자가 보기에 좋지않다 |
◎ 순위함수(order by를 유의해서 사용)
- 조회되는 컬럼 값에 순서를 부여하여 조회할 때
| 함수 | 기능 | 사용법 |
| 조회되는 컬럼 값에 순서를 부여하여 조회할 때 사용한다 order by와 따로 사용하지 않고, order by를 함수에 넣어서 사용한다 |
||
| rank() over() | 같은 순서가 발생한다 | rank() over(order by 정렬할 컬럼명) |
| row_number() over() | 같은 순서가 발생하지 않는다 | row_number() over(order by 정렬할 컬럼명) |
| partition by | 구분할 컬럼을 정해 순위를 조회한다 | partition by 구분할 컬럼명 |
※ 같은 순서가 발생하는 것보다 발생하지 않는것이 좋기 때문에 row_number() over()를 더 많이 사용한다
○ 순위함수 연습해보기
| 함수 | 예시코드 | 실행 |
| 사원테이블에서 사원번호, 사원명, 연봉, 연봉의 순서 조회 | ||
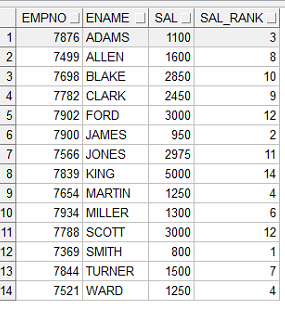
| rank() over() | select empno, ename, sal, rank() over(order by sal) sal_rank from emp; rank() over() 함수는 같은 순서가 발생한다 |
 |
| select empno, ename, sal, rank() over(order by sal) sal_rank from emp order by ename; order by절을 따로 빼서 함께쓰면 순서가 꼬인다 |
 |
|
| row_number() over() | select empno, ename, sal, row_number() over(order by sal) sal_row_num from emp; row_number() over() 는 같은 순서가 발생하지 않는다 |
 |
| 사원테이블에서 부서번호, 부서별 연봉순위, 연봉, 사원명 조회 | ||
| partition by | select deptno, row_number() over(partition by deptno order by sal) as sal_deptno, sal, ename from emp; partition by를 통해 정렬할 파트(구역)을 나눌 수 있다 |
 |
| select deptno, row_number() over(partition by deptno order by sal) sal_deptno, sal, ename from emp where deptno = 30; + where절을 통해 특정 구역의 순위만 볼 수도 있다 ==partition by를 쓰지 않아도 같긴하다 |
 |
|
| 사원테이블에서 직무, 직무별 연봉순위, 연봉, 사원명 조회 단, 같은 연봉이 존재한다면 같은 순위를 가진다 |
||
| partition by | select job, rank() over(partition by job order by sal) sal_rank_job, sal, ename from emp; |
 |